Building an AI Knowledge Base with Semantic Cache
A weekend proof of concept using AWS Bedrock, Amazon Nova, and self hosted Qdrant. The part I am most happy with is not the AI part. It is the semantic cache.
The Build
I sometimes build small things just to stay curious. This weekend I want to share one of them. A personal proof of concept, an AI knowledge base using AWS Bedrock, Amazon Nova, and self hosted Qdrant (a vector database). Nothing groundbreaking. But building it taught me something practical about cost engineering in AI systems.
The part I am most happy with is not the AI part. It is the semantic cache.
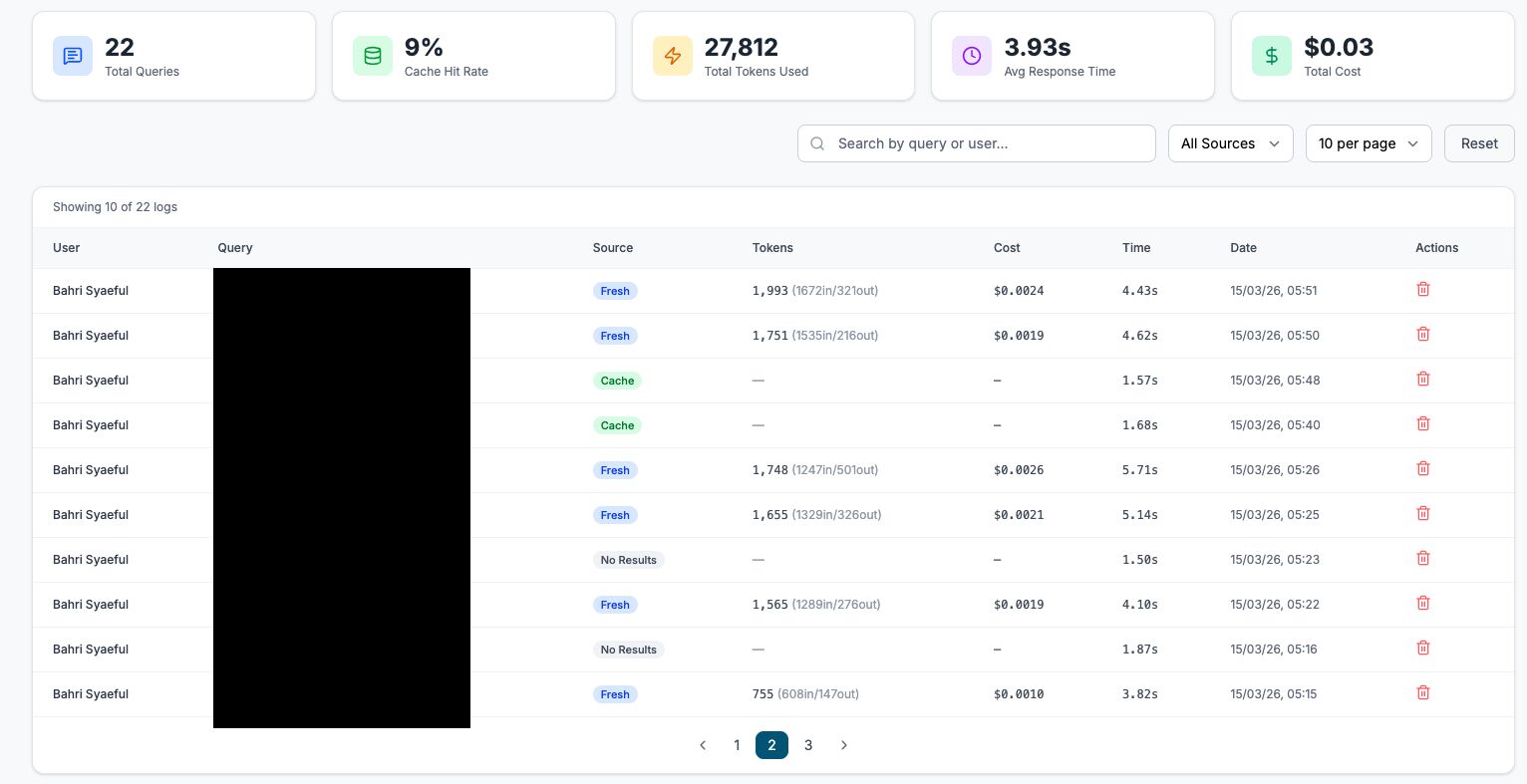
The Numbers
The Semantic Cache
Every query costs roughly $0.003 to process through the LLM. That sounds tiny until you imagine 50 staff asking similar questions about the same documents every week. With a 30 to 50 percent cache hit rate, effective cost per query drops to around $0.002 or less. The cache does not match exact words. It matches meaning.
Cost Transparency
One thing I confirmed by actually building this: AWS Bedrock returns the exact token count in every API response. Input tokens, output tokens, total. No estimation. Cost calculation is just multiplying those numbers by the published price.
So I built a dashboard around that. Every query logged with tokens used, cost, response time, and whether the answer came fresh or from cache. Full audit trail. Anyone can see exactly what the system costs to run, down to the cent.
Why It Matters
Having worked in international development and government systems for a while, budget scrutiny and data accountability are real concerns when exploring anything new.
Being able to show exactly what the system costs per query makes that conversation a lot easier. Pay per use pricing also means you are not committing to a $500/month subscription just to experiment. Start small, measure everything, scale only when it makes sense.